机场客流量的时空分布预测冠军方案
为了有效利用机场资源,机场正利用大数据技术,提升生产运营的效率。机场拥有巨大的旅客吞吐量,与巨大的人员流动相对应的则是巨大的服务压力。安防、安检、突发事件应急、值机、行李追踪等机场服务都希望能够预测未来的旅客吞吐量,并据此提前调配人力物力,更好地为旅客服务。
一、赛题背景
1.1 业务理解
本次大赛以广州白云机场真实的客流数据为基础,它包含每天数万离港旅客在机场留下百万级的数据记录。参赛队伍需要通过数据算法来构建客流量预测模型,具体而言是预测特定时间、特定无线AP的连接人数。
1.2 数据理解
赛题给出六张表,涵盖了四个方面的数据:无线历史连接数据、航班排班数据、地理位置信息及旅客行为信息。
1.2.1 历史连接
无线历史连接数据包含的是机场无线AP历史连接信息,格式如下:
| wifi_ap_tag | passenger_count | time_stamp |
|---|---|---|
| E1-1A-1<E1-1-01> | 15 | 2016-09-10-18-55-04 |
| E1-1A-2<E1-1-02> | 15 | 2016-09-10-18-55-04 |
其中,wifi_ap_tag是无线AP的名称,passenger_count是在某一时刻接入该无线AP的设备数量;time_stamp是精确到秒的时间戳。
无线AP名称包含很多信息,以“-”分割后,第一组是区域编号,第二组是无线AP组编号(其中第一位数字是楼层信息),第三组是组内编号。以“E1-1A-1<E1-1-01> ”为例,该无线AP位于E1区域的1楼,组号为A。可见,可以通过无线AP的名称推断出此AP粗略的位置信息。
1.2.2 航班排班
每天的半夜两点,机场就会给出接下来一整天的航班排班表,格式如下:
| flight_id | scheduled_flt_time | actual_flt_time | bgate_id | arrival_departure |
|---|---|---|---|---|
| HU7848 | 2016/9/17 23:40:00 | 2016/9/18 23:59:00 | B226 | D |
| AF9718 | 2016/9/18 2:10:00 | 2016/9/18 2:34:00 | / | A |
其中flight_id是航班id,scheduled_flt_time计划起降时间,actual_flt_time是真实起降时间,bgate_id是登机口信息,arrival_departure是起飞OR降落标记(D表示起飞,A表示降落)。在预测区间上actual_flt_time字段为空,降落的飞机没有登机口信息。注意,这张表里面使用的时间是格林威治时间,而北京时间=格林威治时间+8小时。
航班排班确定之后,一整天的旅客登机位于哪个登机口就已经确定,借此可以推断出在某个时刻哪些登机口附近的旅客较多。
1.2.3 地理位置
地理位置涉及两张表,一张表给出每个登机口分别在什么区域,另一张表给出部分无线AP的坐标信息。
我们最终目标是“预测客流量的时空分布”,在空间方面,可以利用这些地理位置信息将航班起降与相应区域关联起来。
1.2.4 旅客行为
旅客行为设计两张表:安检表和行程表。
安检表包括旅客安检信息,格式如下:
| passenger_id | security_time | flight_id |
|---|---|---|
| ZH9615*028*10SEP16 | 2016/9/10 04:30 | ZH9615 |
| HO1078*046*10SEP16 | 2016/9/10 04:30 | HO1078 |
其中passenger_id是旅客编号,security_time是安检时间,flight_id是航班号。
行程表包括旅客进入、离开机场的信息,格式如下:
| passenger_id | flight_id | flight_time | checkin_time |
|---|---|---|---|
| 25296480 | FM9358 | 2016/9/11 13:50 | 2016/9/11 11:57 |
| 25296482 | CZ379 | 2016/9/11 14:00 | 2016/9/11 11:55 |
其中passenger_id是旅客编号,flight_id是航班号,flight_time是起飞时间,checkin_time是值机时间。注意,这里的旅客编号与安检表中的旅客编号是不通的。
旅客行为信息可以在两个方面发挥作用,一方面是通过调研这些数据辅助模型构建,另一方面在预测近短期(如11日凌晨00:00-02:59)内的连接数时可以做到更加精确。
1.3 赛题解读
要直接解决的问题是利用机场大量数据来预测每个时间点、每个无线AP的连接人数,这一结果可以反映机场客流的时空分布。题目中为了减少噪声对建模过程的影响,取最小时间单位为10分钟,即预测每10分钟的平均值,比如11日00:00-00:09这10分钟上的均值是第一个预测目标点。
首先,我们以同一时间点、同一无线热点的历史连接数据作为基础模型;其次,以航班起飞这一事件对基础模型进行修正;再次,通过划分子模型降低维度来优化模型;最后,对11日凌晨3个小时引入近期信息进一步提升预测精度。
二、核心思路
我们的算法基于GBRT回归模型,包含多方面特征:历史特征、航班特征、位置特征与时间特征等。
2.1 特征详述
2.1.1 历史特征
通过无线AP的同一时间点历史连接数据可以大致推算出当前时刻该无线AP的连接数,这可以作为整个模型的基础。从下图可以看出,真实值一直围绕着历史均值上下浮动,而三种历史均值在不同情况下各有优势。我们计算了包括AVG、MIN、MAX、STDDEV多个指标,计算方式有同点、同时段、同区域三种,时间窗口为最近1/2/3/4/5/6/7/14/30天。
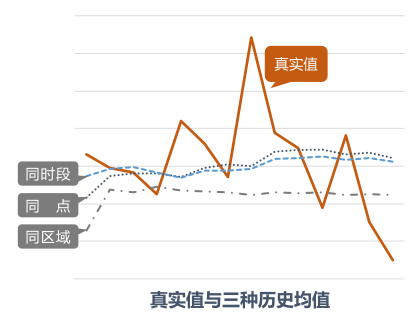
AVG、MIN、MAX与STDDEV分别用于衡量均值、下限、上限与变化剧烈程度。最直接的方式是对同时间点、同无线AP历史数据进行聚合。为了减少时空噪声的影响,我们还考虑了同时段(该点上下30分钟内)、同无线AP的历史数据与同时间点、同区域(无线AP组号相同)内无线AP的历史连接数据。为了涵盖连接数的时序变化趋势,聚合窗口由短到长分为9种。
2.1.2 航班特征
虽然基于时序分析的历史特征可以为预测提供一个很好的基准值,但很多波动无法刻画。这些波动往往是由航班起飞、到达这些事件引起的,需要通过航班特征来刻画。从下图可以看出,旅客一般提前1.5个小时左右进行安检,然后进入候机区等待,所以我们统计了所有登机口该时间点后10/30/60/90/120/180/240分钟内起飞航班数量,分为多个时间窗口是由于有的旅客在10分钟内起飞,有的旅客在1个小时内起飞;另外,航班经常晚点10-30分钟,所以我们统计了所有登机口该时间点前10/30/60分钟内起飞航班的数量,分为多个时间窗口是由于有的旅客晚点10分钟,有的旅客晚点半个小时。注意,我们对那些共享飞机的航班进行了合并处理。
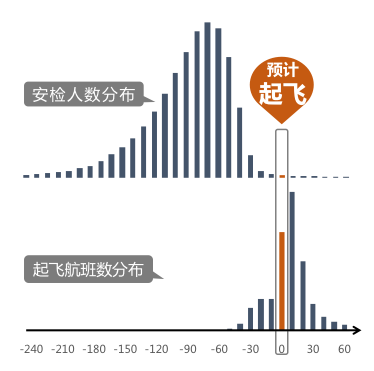
到达航班对于接机区、中转区与取行李区的人流分布有着影响较大。因为到达航班没有区分具体的登机口,我们统计的是该时间点前后10/30/60/90分钟内到达航班的总数量,在此我们也对那些共享飞机的航班进行了合并处理。
2.1.3 时间特征
时间信息可以帮助我们区分特殊的时间段,比如夜间和节假日等,包含了天内分钟偏移、星期与节假日等信息。
天内分钟偏移是天内分钟的索引值,直观地讲是该时间点是天内第几个10分钟,比如00:00-00:09的天内分钟偏移为0,因为它是天内第1个10分钟。它可以帮助我们区分天内不同时段:夜间和白天的客流分布很可能是不同的。
星期与节假日信息可以帮助我们区分特殊的日期。星期方面直接将星期几作为特征,而节假日方面我们把每天分为五种情况进行标注:0表示工作日,1表示最后一个工作日,2表示假期第一天,3表示假期中,4表示假期最后一天。
2.1.4 位置特征
位置特征可以帮助我们区分特殊的区域,包含无线AP所在的区域、楼层与其坐标值、所在组的编号等信息。通过这些信息,算法可以为不同区域分别考虑:有的区域连接数一直很多,有的区域连接数变化剧烈。
2.2 模型建立
我们最初的模型是用单个回归模型预测所有区域,但这样做会导致输入的维度非常高。实际可以用于训练的数据却十分有限,所以会产生过拟合现象。为了减少过拟合,需要向模型中合理地引入先验知识。
我们观察到可以将白云机场分为四个区域:登机区域 (W1、W2、W3、E1、E2、E3)、T区域、WC区域与EC区域。对于候机区域的无线AP点,只需要考虑与之距离最近6个登机口的起飞航班特征;对于T区域,只需要考虑W、E这两个大区域的总起飞航班特征及T区域内AP组号;对于WC区域,只需要考虑W1、W2、W3这三个登机区域的总起飞航班特征及WC区域内AP组号;对于EC区域,只需要考虑E1、E2、E3这三个登机区域的总起飞航班特征及EC区域内AP组号。另外,将B901-B909的航班起飞特征放在WC区域,因为这9个登机口位于WC区域的一楼。将单个回归模型分为四个子模型后——从单个回归模型预测所有区域到为不同区域分别建模,输入的维度大幅度降低。
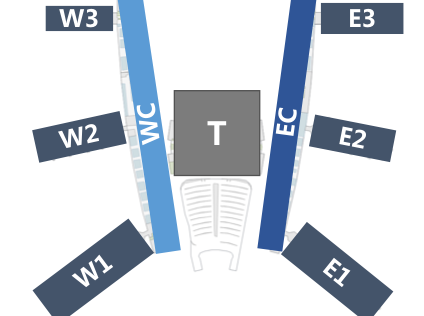
另外,对于时间类特征,如星期、天内分钟偏移等,我们将其看作1维整数,而不使用one-hot高维编码,这一技巧进一步降低了输入维度。与线性回归等参数回归模型不同,GBRT是基于空间划分的回归模型,对于诸如星期这类有序变量,它可以根据训练数据将其合理地划分为多个区间,比如可以将星期划分为[星期一, 星期四]、[星期五, 星期日]两个区间。
最后,对于11日凌晨的3个小时(00:00-02:59),通过为它们引入10日夜晚的近期信息,比如10日最后一个时间点的连接数及安检信息等,可以进一步优化预测结果。也就是说,预测短期内客流分布可以做得更准确。
三、 经验总结
本次比赛收获良多,经验总结如下:
第一,工欲善其事,必先利其器。用合适的工具做合适的事情,比如利用文档管理算法设计及模型迭代,利用Python自动生成SQL代码,利用PAI命令执行训练及预测等。
第二,莫要画地为牢。思路要开阔,不能过于局限,比如只局限于使用历史连接数据,或只局限于使用单一模型等。
第三,三个臭皮匠胜过诸葛亮。团队合作好于单枪匹马,团队合作不但可以在有限的时间内尝试更多思路,还能互相找出对方的思维误区。
第四,逆水行舟,不进则退。无论当前成绩如何,都要不断地优化模型,否则迟早会被人超越。虽然,我们团队前期优势明显,如果就此懈怠,没有继续优化模型,很难保持第一到比赛结束。
第五,格局决定输,细节决定赢。不同梯队是由于算法整体架构不同,同一梯队内排名是由于细节关注程度不同。
四、相关资料
答辩PPT: 下载